
Today’s platform update includes two features that improve workflow performance for users who are doing heavy, real-time data processing within the workflow engine. There are a number of use cases that, prior to this release, fell just outside the capabilities of workflows, and these updates now make those use cases achievable.
While Jupyter Notebooks are still best for batch analytics, they can be overwhelming for those without a programming background. Today’s release empowers such users to take advantage of the drag-and-drop workflow interface to accomplish more of their post-processing outside of a notebook environment.
Parallel Loop Node Executions
It is quite common to loop over arrays of data stored on a payload and perform operations on each iteration, and sometimes those operations can be quite time consuming. A poorly constructed workflow, or an excessively large array, can then result in a timeout error, leaving iterations unprocessed.
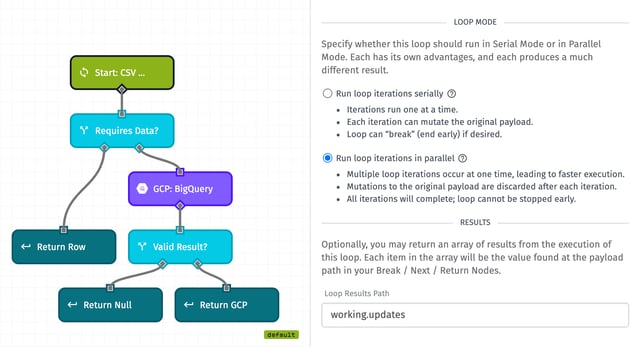
Today we are exposing the ability to run Loop Nodes in parallel (multiple iterations at one time), whereas previously they could only run serially (one after the other). A parallel loop can run as much as five times faster than a serial loop, drastically reducing the risk of timeouts.
Parallel loops do come with the drawback that the original payload cannot be modified, so we’ve also added the ability to define a result per iteration and return an array of each iteration’s results. Most workflows can easily be adjusted to utilize result-returning parallel loops.
Scheduled Workflow Runs
Many users already take advantage of workflow-to-workflow invocation through the Workflow Trigger Node, which allows for spinning off complex calculations to a new process - and avoiding timeout issues. Today’s release extends the functionality of this node to allow for scheduling those invocations at a later time.
A common use case, especially for users taking advantage of our Edge Compute features, is to collect state reports locally on a device and then batch-report all of that state data the next time the device has an Internet connection. If those state reports pile up enough, this can lead to timeouts to third-party API calls or Device State Triggers failing to fire due to concurrency limits.
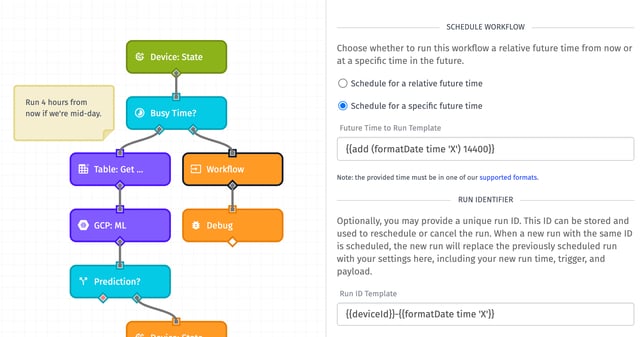
If post-processing of state data can wait, users can spread the executions out over a wider time range, or schedule those workflow runs to occur when they expect lower trigger volume - such as the middle of the night. Also, scheduled runs can later be canceled, or pushed further into the future depending on conditions defined by the user.
Instance Manager APIs
With this update, we’re also introducing our Instance Manager APIs: a set of endpoints that help Losant resellers and enterprise customers programmatically manage the organizations under their umbrella. Using these endpoints, instance managers can:
- Create new organizations, update resource limits, and temporarily disable organizations
- Add Losant users directly to managed organizations
- Generate resource usage reports, including payload and device counts
If you are interested in utilizing this suite of endpoints, contact your Losant account manager to learn more.
Other Updates
As always, this release comes with a number of smaller feature improvements, including:
- Devices queries now support connection status, including by the timestamp they last connected or disconnected. This allows for returning, for example, a list of devices that have been disconnected for more than 24 hours.
- Data Table Dashboard Blocks now support a “Custom” column for rendering images, Markdown, and string templates, much like the Device List and Event List blocks.
- We’ve added an Access Key: Create Node, which allows for generating a set of credentials for authenticating with the Losant Broker in a workflow run. We expect this node to be used often in conjunction with the Device: Create Node in a dynamic registration flow.
- The Array Node now supports the
sliceoperation, which allows for quickly cloning a subsection of an array stored on your payload. - The Workflow Error Trigger is now guaranteed to retain the original payload’s
replyIdproperty, which ensures that an Experience Endpoint request can receive an appropriate response using the Endpoint Reply Node.
Template Library Updates
We’re continuing to grow our Template Library with new entries designed to demonstrate Losant best practices, shorten time to market, and improve end user experience. We’ve added the following templates since our last platform update:
- Auth0 Experience User SSO: Demonstrates how to use Auth0 to manage Experience Users, including a number of SSO providers exposed through the service.
- Experience User File Upload: Allows Experience Users to upload files larger than the maximum workflow payload size to Application Files.
What’s Next?
With every new release, we listen to your feedback. By combining your suggestions with our roadmap, we can continue to improve the platform while maintaining its ease of use. Let us know what you think in the Losant Forums.