
Overall, the Internet of Things will not work without intelligence and machine learning. IoT is not only about collecting the data, but it’s also focused on obtaining value from the data after we’ve acquired it. Attaching sensors to everything only becomes worthwhile when we can predict, control, and make decisions in response to the data.

Now, as we collect massive amounts of IoT data, our ability as humans to make sense of it becomes quite the challenge. To be more efficient, a process is needed that will automatically and in realtime collect data, make predictions, and react. Machine learning and a complete toolchain that supports this model are required. Here is where Google Cloud Machine Learning and the Losant IoT Platform comes in.

With these platforms, the process of collecting, predicting and deciding becomes simplified. Google Cloud Machine Learning Engine is a managed service that enables you to build, deploy, and scale machine learning models easily. Losant is an enterprise IoT Platform that provides the building blocks to create scalable IoT solutions. Together, Google Cloud and Losant provide a system that can ingest data, run the machine learning model, predict an outcome, react, visualize data, and generate alerts. When combined, these tools provide the following benefits:
- Quick time to production
- Increased operational efficiencies
- Overall cost reductions
- Scalable, flexible, and reusable IoT Architecture
This system and toolchain we described earlier is a key component to building a Predictive Maintenance System (PdM). In an industrial environment, a functioning PdM can predict problems in equipment before they occur—to perform corrective maintenance of the equipment before failure.
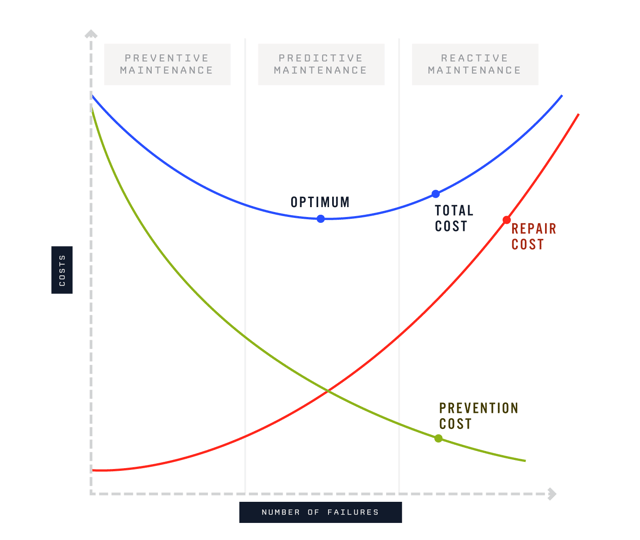
To accomplish PdM, most implementations use a form of condition monitoring that leverages a mixture of sound and vibration analysis to decide when a machine may be working outside of normal conditions. Once the condition monitoring is in place, parsing through thousands of data points is necessary to decide what factors truly affect the status of the machine. Without machine learning, this task is nearly impossible.

Use Case
Acme Industrial is launching an initiative to improve internal processes and monitor the total health of the Acme facilities. Ideally, this system will generate an alert if there are any problems ahead. Using the same data set and insight, Acme can also determine the health of their facilities as the PdM will have details about the current status of equipment in the facility.
To create this PdM, Acme must first decide and implement four key components:
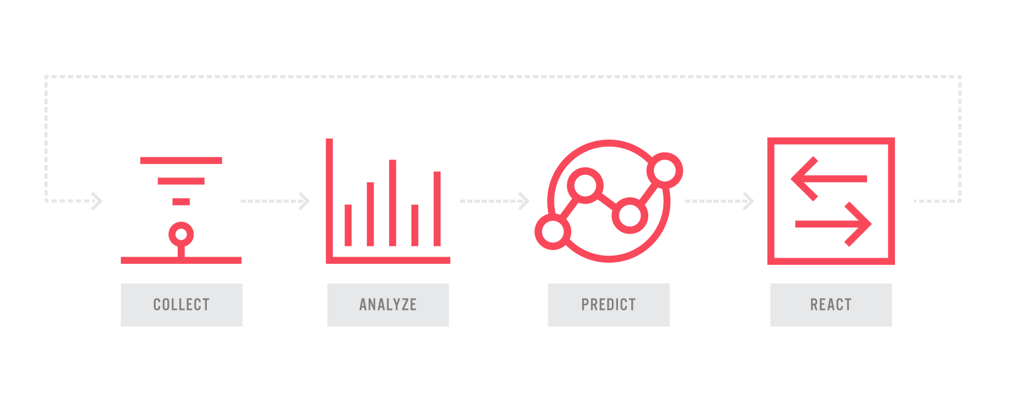
Collect
Acme Industrial has thousands of machines in their manufacturing facilities. To detect problems, Acme will use a form of vibration analysis. Vibration analysis is efficient on most rotating equipment, which most of the machines in their facilities contain. To calculate vibration, Acme engineers will attach accelerometers to each of the machines sending the vibration data to the Cloud. Acme now has a data collection process in place.
Analyze
Next, Acme must determine the parameters that dictate if their machines are failing or not. Unfortunately, machine learning won’t automatically predict problems or anomalies in data. You must first start with a problem or a question. Then, through machine learning, an answer can be found. Here is Acme's question:
Can we detect if a machine is likely to experience a failure in the near future?
In machine learning, this is a considered a classification problem because Acme is looking for discrete answers in a data set. Acme's data set would be all of the vibration data collected from the machines. Acme is finding one of two things: the machine is operating normally, or the machine is likely to be experiencing a failure.
To determine what’s failing or not, Acme must have enough data in each example to learn from it. Before Acme begins to predict when a machine will fail, they must have a large enough data set that provides examples of when the machines are failing and when the machines are operating normally. A good strategy to do this is to collect data from all the machines running in normal conditions. When a machine fails, we can capture the data during a specific period before the machine failed. This newly sliced data collected becomes my “likely to experience a failure” data set.
Predict
With a data collection process in place, a complete analysis, and data sets for training and testing, Acme can now build a model to answer the question.
Convolutional neural networks (CNN) are typically used to classify images. When a typical image classification model sees an image, it takes a long list of numbers. This list of numbers can be broken into subsets of 3 that represent R, G, B values of a pixel. Then, the model will identify which pixel(s) in that image determine whether or not that image contains the desired answer.
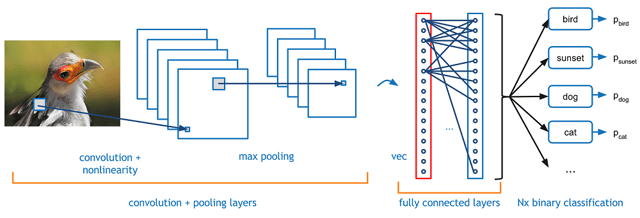
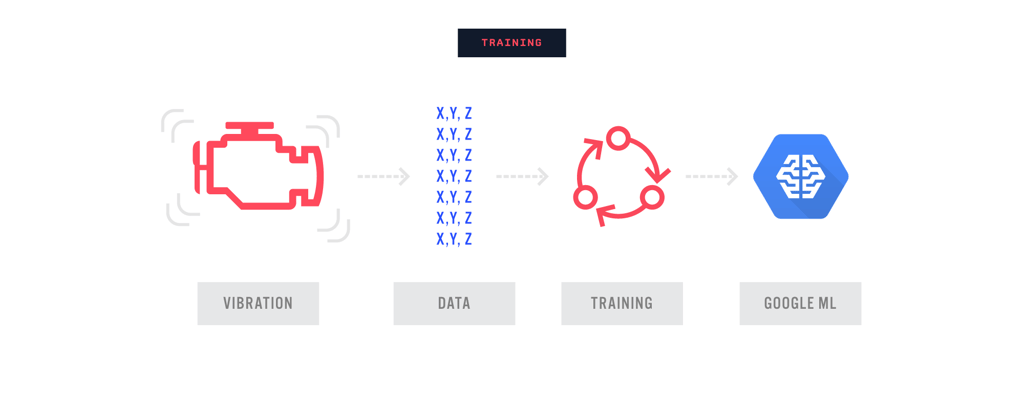
Acme's machine failure detection problem directly correlates to the image classification problem. From the vibration data collected, each accelerometer will output values of X, Y, and Z — data similar to R, G, B — then using a CNN we can similarly identify which vibration parameter(s) determines problems in our machines, or “likely to experience failure.”
Training is a very iterative process that can be done in the cloud. After training the model, Acme found that using this method we can predict with high accuracy if the machines in our test set are “likely to experience failure.”
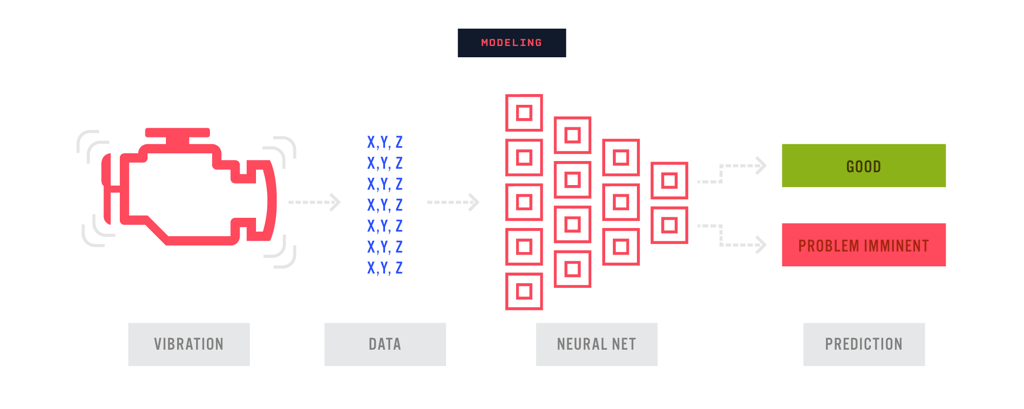
Acme will now be able to use this model to predict when a problem is likely to occur on a machine. Along with a percentage likelihood, the model will also output a percentage confidence of the prediction. Acme can combine the confidence and prediction to determine when to perform corrective maintenance on the machine. Overall, this insight on a wide array of machines will give Acme the ability to calculate the health of the entire facility.
React
A requirement of the PdM is to have an automated process from data collection to decision. With a prediction system in place, a reaction engine is needed to make decisions and generate notifications.
When a machine reports a vibration sample to the model, the model can decide if the machine is operating normally, or if the machine is likely to be experiencing a failure. When normal, no action needs to take place. While experiencing a failure, a support ticket can be created immediately to alert the necessary stakeholders.
Solution
The end solution to Acme's problem and provides the most benefit leverages Google Cloud Machine Learning Engine (Google Cloud ML) and the Losant IoT Platform.
Google ML Engine supports training and deployments of TensorFlow models in the cloud. After training a TensorFlow neural network to detect machine failures, Acme can deploy and use the model to make predictions.
 The hardware attached to the machine is reporting a vibration sample to Losant at a fixed interval. The Acme application in Losant contains a workflow that is listening for the vibration sample using a Device Trigger.
The hardware attached to the machine is reporting a vibration sample to Losant at a fixed interval. The Acme application in Losant contains a workflow that is listening for the vibration sample using a Device Trigger.
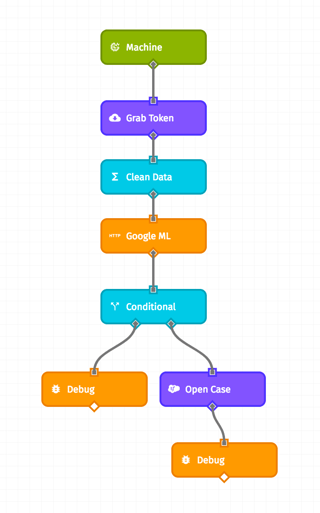
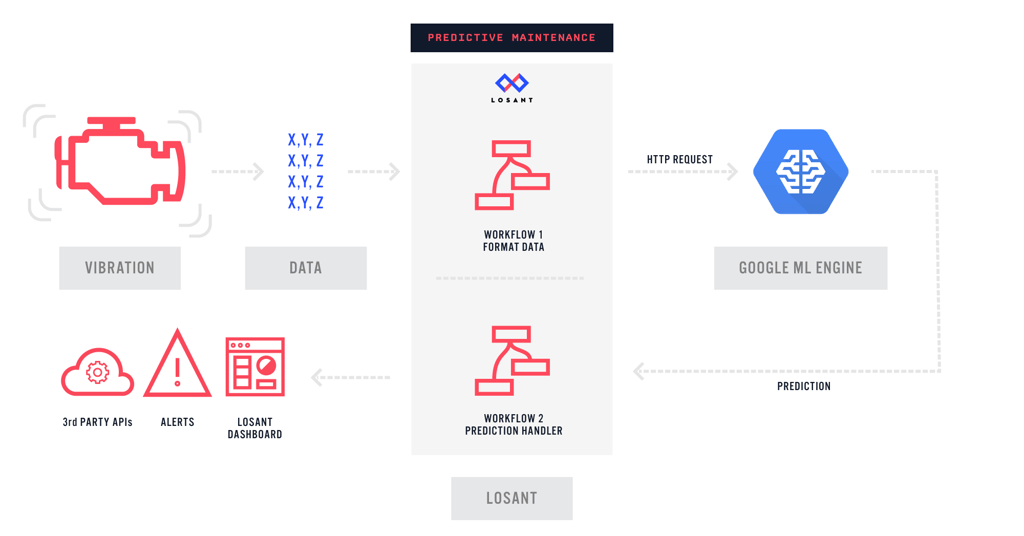 This workflow will first reshape the data. Google ML Engine supports running data through hosted models with little latency via an API. This gives Acme the ability to make an API call directly to the Google ML Engine in the workflow. After a prediction is received, we can decide what to do next. In the example below, a positive result will trigger a Salesforce case ticket to be opened.
This workflow will first reshape the data. Google ML Engine supports running data through hosted models with little latency via an API. This gives Acme the ability to make an API call directly to the Google ML Engine in the workflow. After a prediction is received, we can decide what to do next. In the example below, a positive result will trigger a Salesforce case ticket to be opened.
Conclusion
This system and toolchain support a growing IoT architecture. With Google ML Engine, Acme can continually deploy, re-train, and re-deploy models to gain more efficiencies. Changing business logic or decisions made from the predictions are a simple drag-drop update to the interface in Losant. Additionally, not only can Acme iterate quickly, but Acme can create new models to answer more questions, and the PdM system can scale to support it.
If you are ready to improve your predictive maintenance through machine learning, contact us.